一种文本分类数据挖掘的技术
来源:岁月联盟
时间:2010-08-30
| 词条 | 编号 | 同义词 | 文档频数 |
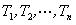 )构成,每一词条都赋以一定的权值 ,从而每一篇文档被映射为由一组词条矢量形成的向量空间中的一个向量。文本的匹配问题便可转化为向量空间中的向量匹配问题处理。 对于词条权值 的处理,在文本学习中最常用的是TF*IDF表示法,它是一种文档的词集表示法,所有的词从文档中抽取出来,而不考虑词间的次序和文本的结构。综合考虑词条对文档的区分度、词频等因素,我们改进了传统的TF*IDF表示法,提出权值公式(1)。再考虑到高频词、低频词的问题,对权值 进行规范化,得到权值公式(2)。表明公式(2)有较高的合理性和较好的分类效果。
)构成,每一词条都赋以一定的权值 ,从而每一篇文档被映射为由一组词条矢量形成的向量空间中的一个向量。文本的匹配问题便可转化为向量空间中的向量匹配问题处理。 对于词条权值 的处理,在文本学习中最常用的是TF*IDF表示法,它是一种文档的词集表示法,所有的词从文档中抽取出来,而不考虑词间的次序和文本的结构。综合考虑词条对文档的区分度、词频等因素,我们改进了传统的TF*IDF表示法,提出权值公式(1)。再考虑到高频词、低频词的问题,对权值 进行规范化,得到权值公式(2)。表明公式(2)有较高的合理性和较好的分类效果。 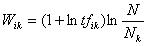 (1)
(1) 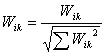 (2)式中, 表示词条在文档 中的出现频数,N表示分类体系数目, 表示词条的文档频数。 经过以上步骤,得到的特征向量的维数是非常高的,如此高维的特征对即将进行的分类学习未必全是重要、有益的,而且高维的特征会大大增加机器的学习时间而产生与小得多的特征子集相关的学习分类结果。这便是特征提取所要完成的工作。特征提取算法一般是构造一个评价函数,对每个特征进行评估,选取评估分值高的、预定数目的最佳特征作为特征子集. 文[5]介绍了一些评估函数,我们在系统中简单地选取了权值前50位特征组成最终的特征向量。2. 3 特征匹配与分类 文本转化为向量形式并经特征提取以后,便可以进行分类挖掘了,即特征匹配。机器学习领域常用的分类算法有:朴素贝叶斯分类法、K-最近邻参照分类法。我们在系统中采用了检索技术中的相似度方法。假设样本文档为U,待学习文档为V,两者的相似程度可用向量的夹角来度量,夹角越小则相似度越高。相似度的公式为(3)。在大于给定阈值情况下,取相似度高的类别作为文档V的类别,若均低于阈值,则提交给用户请求人工分类。
(2)式中, 表示词条在文档 中的出现频数,N表示分类体系数目, 表示词条的文档频数。 经过以上步骤,得到的特征向量的维数是非常高的,如此高维的特征对即将进行的分类学习未必全是重要、有益的,而且高维的特征会大大增加机器的学习时间而产生与小得多的特征子集相关的学习分类结果。这便是特征提取所要完成的工作。特征提取算法一般是构造一个评价函数,对每个特征进行评估,选取评估分值高的、预定数目的最佳特征作为特征子集. 文[5]介绍了一些评估函数,我们在系统中简单地选取了权值前50位特征组成最终的特征向量。2. 3 特征匹配与分类 文本转化为向量形式并经特征提取以后,便可以进行分类挖掘了,即特征匹配。机器学习领域常用的分类算法有:朴素贝叶斯分类法、K-最近邻参照分类法。我们在系统中采用了检索技术中的相似度方法。假设样本文档为U,待学习文档为V,两者的相似程度可用向量的夹角来度量,夹角越小则相似度越高。相似度的公式为(3)。在大于给定阈值情况下,取相似度高的类别作为文档V的类别,若均低于阈值,则提交给用户请求人工分类。 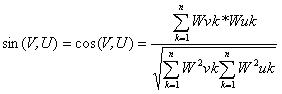 (3)2. 4 文本分类系统 我们采用Visual Basic6.0在Windows2000下开发了一个简单的文本分类系统(STCS),并以Access数据库的形式保存词典、特征向量等。系统采用开放式的结构,分类体系能较容易地进行扩充,针对计算机专业技术文档有较高的分类精度,能满足特定专业领域的应用需求。我们将从网上(http://www.computerapplications.com.cn)下载的500篇计算机类文档作为训练文档和测试文档实验,实验结果表明,当分类体系数目为5时,STCS完成一篇长度为10K的文本的分类大约需要8秒(PC233/256M/windows2000环境下),分类的精度达到79%。3 结束语 本文介绍了数据挖掘中的新的分支—文本挖掘,结合我们所设计的分类系统,重点分析了文本分类的若干关键技术。现阶段我们的系统仅处理文本文档,如何将分类对象扩展到数量巨大的Web文本,这是我们下一阶段工作所要研究的内容。 文献1 王继成.Web文本挖掘技术研究[J].计算机研究与,2000,37(5):513-5202 Feldman R, Dagan I. Knowledge discovery in textual databases [C].In: Proc of the 1st Int’l Conf on Knowledge Discovery.Montreal,1995:112-117.3 Wuthrich B, Permunetilleke D, Leung S et al. Daily prediction of majorstock indices from textual WWW data. In: Proc of the 4thInt’l Conf on Knowledge Discovery. New York,1998:47-494 邹涛.WWW上的信息挖掘技术及实现[J].计算机研究与发展,2000,36(8):1020-1024.5 Koller D, Sahami M. Hierarchically classifying documents using very few words[J].ICML97,1997. 170-178.
(3)2. 4 文本分类系统 我们采用Visual Basic6.0在Windows2000下开发了一个简单的文本分类系统(STCS),并以Access数据库的形式保存词典、特征向量等。系统采用开放式的结构,分类体系能较容易地进行扩充,针对计算机专业技术文档有较高的分类精度,能满足特定专业领域的应用需求。我们将从网上(http://www.computerapplications.com.cn)下载的500篇计算机类文档作为训练文档和测试文档实验,实验结果表明,当分类体系数目为5时,STCS完成一篇长度为10K的文本的分类大约需要8秒(PC233/256M/windows2000环境下),分类的精度达到79%。3 结束语 本文介绍了数据挖掘中的新的分支—文本挖掘,结合我们所设计的分类系统,重点分析了文本分类的若干关键技术。现阶段我们的系统仅处理文本文档,如何将分类对象扩展到数量巨大的Web文本,这是我们下一阶段工作所要研究的内容。 文献1 王继成.Web文本挖掘技术研究[J].计算机研究与,2000,37(5):513-5202 Feldman R, Dagan I. Knowledge discovery in textual databases [C].In: Proc of the 1st Int’l Conf on Knowledge Discovery.Montreal,1995:112-117.3 Wuthrich B, Permunetilleke D, Leung S et al. Daily prediction of majorstock indices from textual WWW data. In: Proc of the 4thInt’l Conf on Knowledge Discovery. New York,1998:47-494 邹涛.WWW上的信息挖掘技术及实现[J].计算机研究与发展,2000,36(8):1020-1024.5 Koller D, Sahami M. Hierarchically classifying documents using very few words[J].ICML97,1997. 170-178.
下一篇:多源数据窗口的数据修改