基于Isabelle的证明信息系统设计
来源:岁月联盟
时间:2010-08-30
1 引言
Isabelle[1]是一种著名的交互式定理证明器,目前已被应用于数学形式化、逻辑研究、机软、硬件以及安全协议的验证等多个领域。使用Isabelle时面临的主要困难是编写定理的证明过程,这一般需要专家级的用户才能完成,这也因此限制了Isabelle进一步的普及。 Isabelle包含许多有重要参考价值的证明信息,例如含有证明方法的证明步骤(proof step),反映当前证明形势和效果的证明状态 (proof state)。这些信息都有助于用户开发新的证明文档,然而目前Isabelle并不提供查询这些信息的功能。 目前已经出现了一些专门为Isabelle构建信息数据库方面的工作与研究。Suzuki[2]为Isabelle建立了一个证明状态数据库,但其中的数据来源于Isabelle的显示,包含的信息较少且数据的提取比较受限。另外,上存在一个Isabelle的理件(theory file)库[3],其中收集了大量的在不同领域应用Isabelle开发的证明脚本。要浏览这些文档的具体证明过程,必须用Isabelle载入并执行文档。这一过程是比较耗时并且需要用户具有运行Isabelle的环境。 本文提出了一个证明信息系统。该系统以关系数据库为基础,并提供可分别提取证明步骤和证明状态的工具,目标是为用户提供一个简易的证明信息搜索平台。该系统面向的用户主要是用Isabelle来编写证明文档的专家,也可被一般用户用来作为学习了解Isabelle证明过程以及一般数学逻辑知识理论的一个工具。2 Isabelle
Isabelle采用的编程语言是函数式编程语言ML[4](Meta Language)。Isar是Isabelle中专门用于书写证明过程的语言,用这种语言编写的证明脚本具有一定的可读性。 以下是与Isabelle相关的重要术语及其定义: (1)证明脚本:为了证明定理而由用户用Isar语言编写的证明文本。 (2)证明行:一行证明脚本。 (2)理论文件:主要是为证明某一个理论中部分或所有定理编写的证明脚本文件。除定理及其证明之外,文件中还有相关的常数和操作符定义、注释等。 (3)证明步骤:完成一步证明的证明脚本。定理的所有证明步骤组成一个定理的完整证明脚本。以下是HOL(高阶逻辑)中与函数相关的理论文件Fun.thy中的引理expand_fun_eq的证明步骤: 0) lemma expand_fun_eq: “f = g” = (! X. f(x) = g(x))” 1) apply (rule iffI) 2) apply (simp (no_asm_simp)) 3) apply (rule ext, simp (no_asm_simp)) 4) done 其中,apply和done是Isabelle的两个证明关键字,apply表示应用;done表示结束当前证明;apply后面的语句表示应用的具体证明策略入规则、方法等。 (4)证明状态:证明时产生的状态,主要信息是当前剩余的子目标。图1是证明引理expand_fun_eq时执行到第1步时的证明状态显示。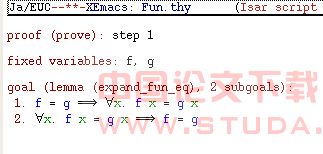 图1 Isabelle的证明状态显示 由上图可知,原引理已被化成两个子目标并等待下一步的证明。
图1 Isabelle的证明状态显示 由上图可知,原引理已被化成两个子目标并等待下一步的证明。3 系统设计
该信息系统的设计目标是利用Isabelle提取证明步骤和证明状态,并用标准的数据库技术加以处理,为用户提供一个网络界面可以迅速查找和浏览这两种证明信息。3.1 结构设计
按照系统数据处理和功能的相关性,可以将此系统分为3个模块: 提取界面、数据库和搜索界面,如图2所示: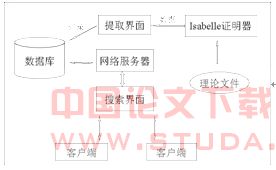 图2:系统模型 其中,提取界面用于提取所需数据;数据库用来存储提取来的纪录数据;搜索界面用于客户端对数据库的访问。 系统的工作流程为:首先,用Isabelle载入理论文件并启动证明过程。这时Isabelle会按从上到下的顺序对文件中的每个定理进行证明,可逐步进行,也可成批处理。无论是用何种方式,都可用提取界面提取所有的证明步骤和证明状态数据。将二者的记录数据插入到数据库后,便可以在客户端利用搜索界面访问数据库,从而最终实现对这两种信息的查找。 根据上面介绍的结构模型及其工作流程,此系统的设计可分为三个部分:提取界面设计、数据库设计及搜索界面的设计。
图2:系统模型 其中,提取界面用于提取所需数据;数据库用来存储提取来的纪录数据;搜索界面用于客户端对数据库的访问。 系统的工作流程为:首先,用Isabelle载入理论文件并启动证明过程。这时Isabelle会按从上到下的顺序对文件中的每个定理进行证明,可逐步进行,也可成批处理。无论是用何种方式,都可用提取界面提取所有的证明步骤和证明状态数据。将二者的记录数据插入到数据库后,便可以在客户端利用搜索界面访问数据库,从而最终实现对这两种信息的查找。 根据上面介绍的结构模型及其工作流程,此系统的设计可分为三个部分:提取界面设计、数据库设计及搜索界面的设计。3.2 提取界面设计
按照提取数据的种类,此界面可进行:(1) 证明步骤提取 要从理论文件中提取出每一个证明步骤,可以利用以下算法,共有六个步骤: 1) 去注释:注释可以位于理论文件的任何位置,形式为(*… *)并可以嵌套使用。去除这些注释的目的是避免它们对提取过程造成干扰,因为注释中和证明关键字相同的词语很容易被误认为是证明步骤的开始而导致证明步骤的错误识别; 2) 证明行获取:按字符串行来分离去注释后的证明文档,得一长的证明行序列; 3) 分块:按照证明行所属的定理将2)中得到的长序列分成多个子序列,其中可能会涉及到步骤分离的操作; 4) 步骤连接:在每一个字序列中处理多行长步的情况。多行长步是指一个占用了两个或更多证明行的长的证明步骤。所谓的连接就是将这种证明行连成一个完整证明步骤字符串。完成此步,每个子序列就可以正确包含一个定理的所有证明步骤; 5) 结果输出:每一个证明步骤连同理论名,步骤序号、所在定理名作成记录,一同输出到文件。 此算法中第3步中的步骤分离用于处理一行多步的情况。一行多步指的是一行语句中含有2 个或多个证明步骤。例如,引理expand_fun_eq的第1步和第2步可以记在一个证明行中:apply (rule iffI) apply (simp (no_asm_simp)) 这对Isabelle的处理没有任何影响,因为Isabelle能够按照证明关键字来区分每一步。为保证提取过程中每一个证明步骤的完全分离,需要工具将Isablle所有的证明关键字考虑在内并且能把上面的语句提取成这两个纪录:/* 理论名, 定理名, 步骤序号, 证明步骤 */ HOL.Fun expand_fun_eq 1 apply (rule iffI)HOL.Fun expand_fun_eq 2 apply (simp (no_asm_simp)) (2) 证明状态提取 和证明步骤不同,证明状态只在证明过程中生成,不被Isabelle保存。所以这个提取过程的主要困难就在于如何在Isabelle丢弃这些状态之前捕获它们。证明状态在Isabelle中对应的数据类型为state。state类型是一个很复杂的结构类型(相当于C语言中的结构类型),但没必要把其中的所有数据都提取出来,可以有选择性的提取。该系统从每个证明状态中提取的各项数据名称如下表:| 定理名 | 定理内容 | 步骤序号 | 子目标 |
3.3 数据库设计
数据库设计包括表设计、插入数据和建立索引三个过程。首先,合理构造数据库中的表可以有效存储和管理提取到的记录数据。由于证明步骤和证明状态两种信息之间存在差异,所以分别为它们创建数据表。表的设计过程可在数据提取之前进行,即先确定所需的目标数据种类,然后再实现提取界面,这样更具目的性。 其次,在插入数据过程中,用逐条命令插入的方式比较费时,而用文件插入方式显得既方便又快速。 最后,为数据表建立索引,如定理名索引,步骤序号索引等,这些索引可提高数据库的搜索效率。3.4 搜索界面设计
搜索界面主要是为了方便用户对数据库的查询。利用此界面执行的一个典型的搜索过程如下所示: 1) 连接数据库; 2) 接受用户的查询请求; 3) 分析查询请求,生成数据库用的查询请求; 4) 用新的查询请求与数据库通讯; 5) 显示查询结果。 其中,按照数据库中含有的信息种类,第2步中用到的输入界面需要考虑搜索框的设计;第3步涉及到处理查询请求字符串的相关操作;第4步中的请求与记录的匹配过程完全由数据库执行;第5步的主要任务是控制返回的查询结果的输出,例如显示结果数与查询时间、前后翻页等。4 系统实现与测试
本信息系统已经得到实现。其中,提取界面中的相关工具都用ML语言得到实现;数据库系统采用了标准的关系数据库系统PostgresSQL; 服务器软件用的是Apache; 搜索界面采用PHP语言编写;服务器的操作系统为Fedora Core 3,可以运行Isabelle来提取数据;客户端只需要有网络浏览器和网络连接即可。 由于Isabelle的源代码中本身就包含大量的理件,因此利用该系统对这些理论文件进行数据提取和插入后,可认为该系统已具有一个较丰富的证明信息数据库。 用户可以利用理论名、定理名、定理内容中的常数以及子目标的关键字或步骤序号等进行搜索。图3给出了一个利用定理名搜索的例子,即输入定理名expand_fun_eq,可得到与此定理证明相关的来自证明步骤以及状态的信息,即(从左到右):该定理所在理论的名称、定理内容、采用的所有证明步骤及其序号、应用每一步产生的子目标。注:此搜索结果中,引理expand_fun_eq证明的最后一步”done” 被省略是因为它无实际的证明功能。用户在使用本系统的搜索功能时,可以通过网络浏览器进行而不需要安装运行Isabelle软件。这将极大方便用户对证明信息的快速查询。 通过对系统的测试,结果显示:在数据提取以及搜索速度方面,该系统均可以达到预期目标。这主要归功于ML语言在提取界面的直接利用以及标准数据库提供的高效搜索功能。PHP的数据库接口函数也极大的方便了搜索界面的实现。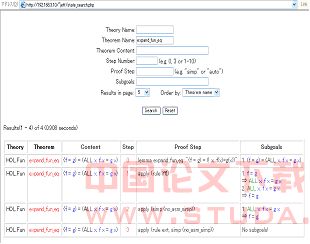 图3: 搜索例 5 结束语 本文给出了一个基于定理证明器Isabelle的证明信息系统的设计方案并给出了具体实现。该系统的设计和实现尝试了将标准的关系数据库技术应用于定理证明领域中的证明信息管理。关于如何从Isabelle以及其他众多的证明脚本中提取出更多有价值的证明信息以改善证明脚本的开发,还有待进一步的研究与测试。
图3: 搜索例 5 结束语 本文给出了一个基于定理证明器Isabelle的证明信息系统的设计方案并给出了具体实现。该系统的设计和实现尝试了将标准的关系数据库技术应用于定理证明领域中的证明信息管理。关于如何从Isabelle以及其他众多的证明脚本中提取出更多有价值的证明信息以改善证明脚本的开发,还有待进一步的研究与测试。