生物序列的一种启发式拼接算法及实现
来源:岁月联盟
时间:2010-08-30
0 引言
对于序列拼接的问题[1],即便在忽略了各种误差的情况下,要作出十分精确的目标序列也是极其困难的。目前,比较普遍的做法是将拼接分为三个阶段[2] ,第一,发现片段交叠;第二,构造片段排列;第三,计算表决序列。1 若干算法
目前,对于一个典型的较小规模测序问题,处理过程可粗略地分为两步:首先用“散弹枪”法将目标分子打散,然后将打散的片段重新拼接起来。 经过实验处理后获得的片段数量多在1000-2000左右,目标分子的长度也仅为30,000bp-100,000bp。 因而将每一个片段作为图的一个顶点,构造一个完全图进行处理是合理的。目前通常的做法是将所有结点即片段两两通过局部比对,除去嵌合片及重复片段,然后采用诸如最短公超串(SCS)、重构(reconstruction)、多连叠(multicontig)等模型来构造片段排列,计算表决,如由X.Huang提出的方法[3]就是这样。 其中,针对SCS模型又有若干种算法,这些算法的传统目标多为寻找Hamilton最大权路径,这可以采用递归搜索策略,但可能需要花费指数时间[5]; 也可以采用贪心搜索策略[6], 其时间复杂度为Ο(n2),这个是目前其他各种算法的基础。对于贪心搜索策略主要有以下两个问题,第一:由于Hamilton难题是NP完全的,故贪心算法并不总是返回最短超串的[1]如图1所示,权为4的边是第一个被考察的,从而另两条权为3的边被丢弃;第二:不适应实际情况,为了解决目标序列上的覆盖缺乏问题,通常会增加随机采样,造成所有片段长度的总和大于目标序列的7-8倍以上,而Hamilton路径将所有节点都加入,这不符合实际。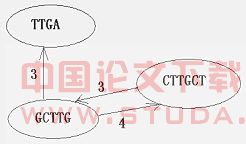
2 启发式算法
我们采用启发式搜索策略构造出近似的目标序列, 基本思想是: 选择两个长度较长且交叠罚分很低的结点作种子,求得两种子的最大权路径,在计算路径的权值时就判断路径长度是否小于目标序列的大致长度,若大于则停止前进,反之则选择新的不属于已有序列的片段作为新的种子进行延伸,直至长度达到目标序列的长度。2.1 准备工作
首先,求出每对片段间的比对计分,采用的方法是半全局部比对[4],其特点是:1.失配计绝对值较大的负分。2.控制失配碱基个数。3.比对两次,第一次A片段的首空格不计分且B片段的尾空格也不计分,第二次反之如图2所示,第一次甲的尾空格与乙的首空格罚分不计分,第二次乙的尾空格与甲的首空格罚分不计分。 第二步,构建一个有向图,将每个片段作为该图的结点,每对结点有两条边。再构建一个n×n的矩阵(n为片段总数),将第一步得到的半全局罚分填入矩阵,这样每对片段有两条边。图中的每一个结点与矩阵的一个元组对应,每条边的权值与矩阵的一个元素对应。
2.2 算法描述
构造图G和以root为根结点的最长路径树T,目标结点集合D,Parent和Child作为两个临时节点,建立一个排序队列Sort_Queue,使用队列Store_Queue存放已处理过的节点,定义int型变量seed[]作为存放种子的数组存放着片段的序号,best[ID]定义为到每个节点的最高罚分与两片段表决距离的比值(初始值为-MAX,ID为片段的编号),目标种子定义为全局变量TargetSeed,TargetLen是目标序列的长度, Min是表示序列无关的罚分阙值。其中图1节点的结构为:Typedef Struct Node *TreeNode{int ID; //节点编号int len //已得序列的长度Node *father}Typedef Struct Link_Node *Link{Tree *Node int dis //节点与目标节点的距离Link *next}long D[][]; //存储罚分的n×n矩阵 Heuristic_Path(G) Initialize Tree T with sorce nodes and clear Sort_Queue Compute the scores of the pieces in pair and fill in D[n][n]While(overlap(seed[0],seed[1])>Min){Random(seed[0])Random(seed[1])//产生两个种子root = seed[0] //作为树根}int id=0//用于记录其他所有节点序号While(id∈ADJ(seed[0])){ Enter_Sort_Queue(id)}i=1 //为种子计数TargetSeed = seed[i] While(True) {//将离TargetSeed最近的节点出列Parent = Get_From_Queue()If( Parent is NULL ) Return Null//找到目标种子,若长度大于目标长//度就返回。 If(Parent is TargetSeed){ If(Parent.len < TargetLen){ i=i + 1 Random(seed[i]) TargetSeed = seed[i] continue } Else break }//end if while( u∈ADJ(Parent) ){ //延伸节点 Child=Try(u ,Parent)} If(Child is false){ Get_out(Store_Queue) }}//End whileD = TraceBack(TargetSeed) //回溯 其中judge(w)用于估算当前节点w到目标节点target的路径距离,这里是当前节点与目标序列的相似度,即:overlap(w,TargetSeed)。 ADJ(u)表示与u的相邻距离大于一个阙值的节点,它的实现即:在矩阵D中搜索下标为u.ID的一列或一行元素,找出所有大于阙值节点编号。 罚分函数overlap()用于两结点的比对罚分,即通过两结点的编号在矩阵D中查找出相应的罚分。Enter_Sort_Queue(w,distance)待处理节点入队列, 依靠对目的地估价距离插入排序:Link p = Sort_QueueWhile(distance > p.dis) p = p.nextp = w节点与目标的比对罚分越低,则与目标的距离越远,因此我们按dis升序排列。 Try(u,Parent)用来尝试从Parent节点移动到u节点是否可行,采取的策略是判断两序列的罚分与表决长度的比值,该值越大则越好,它表明两序列的相关度更高如图3所示:序列3与已知序列的表决结果最好,因为其罚分与序列的长度比值最高。Try(u,Parent){ //如果有更好的父节点则退出If(overlap(Parent,u)/consensus(Parent,u)<best[u]) return false //如果已经在路径中则退出 Else If u already in Store_Queue{ return false}best[u]= overlap(Parent,u) consensus(Parent,u)Enter_Sort_Queue(u,judge(u))}其中的consensus(Parent,u)将结点Parent与u表决,并将表决后的总长度赋给u.len。
3 算法分析
对其时间复杂度分析:我们用n表示图中节点数目,由于是完全图,故初始化的时间复杂度为T1 = Ο(n2),产生种子及树根子节点入列的时间复杂度为T2 = e +Ο(n),每个节点u访问d(u)相邻节点,且检验一次是否已经在处理过的队列中了,时间复杂度为T3 =Ο(en),故其时间复杂度为T =Ο(n2) 对其空间复杂度分析:我们用两个链表Sort_Queue和Store_Queue来存储中间过程的序列,用best[]来存放每个节点,seed[]用来存放种子,故其空间复杂度为S =Ο(n+e)。4 实验报告
我们在配置为PⅣ1.7G,内存256M计算机上用VC6.0编译测试,在测试初始随机产生长度为100,000的序列作为被测试对象,并模拟散弹枪法将原始序列打散得到长度为500-900不等的片段。 实验分四次进行,分别打散3,7,9,11条序列,所得数据如表1,表2所示:表1 贪心算法与启发示算法比较结果| 原序列3条 | 原序列7条 | |||
| 用时 | 罚分 | 用时 | 罚分 | |
| 贪心算法 | 6min | 3722 | 35min | 2702 |
| 启发算法 | 8min | 3011 | 40min | 6836 |
| 原序列9条 | 原序列11条 | |||
| 用时 | 罚分 | 用时 | 罚分 | |
| 贪心算法 | 55min | 3102 | 80min | 1410 |
| 启发算法 | 70min | 6443 | 100min | 6629 |