KMP模式匹配算法探讨
来源:岁月联盟
时间:2010-08-30
在机领域,串的模式匹配(以下简称为串匹配)算法一直都是研究焦点之一。在拼写检查、语言翻译、数据压缩、搜索引擎、入侵检测、计算机病毒特征码匹配以及DNA序列匹配等应用中,都需要进行串匹配。串匹配就是在主串中查找模式串的一个或所有出现。在本文中主串表示为S=s1s2s3…sn,模式串表示为T=t1t2…tm。串匹配从方式上可分为精确匹配、模糊匹配、并行匹配等,著名的匹配算法有BF算法、KMP算法、BM算法及一些改进算法。本文主要在精确匹配方面对KMP算法进行了讨论并对它做一些改进以及利用改进的KMP来实现多次模式匹配。
1 KMP算法
最简单的朴素串匹配算法(BF算法)是从主串的第一个字符和模式串的第一个字符进行比较,若相等则继续逐个比较后续字符,否则从主串的第二个字符起再重新和模式串的第一个字符进行比较。依次类推,直至模式串和主串中的一个子串相等,此时称为匹配成功,否则称为匹配失败。朴素模式匹配算法匹配失败重新比较时只能向前移一个字符,若主串中存在和模式串只有部分匹配的多个子串,匹配指针将多次回溯,而回溯次数越多算法的效率越低,它的时间复杂度一般情况下为O((n-m+1)m) (注:n和m分别为主串和模式串的长度),最坏的情况下为O(m*n),最好的情况下为O(m+n)。KMP模式匹配算法正是针对上述算法的不足做了实质性的改进。其基本思想是:当一趟匹配过程中出现失配时,不需回溯主串,而是充分利用已经得到的部分匹配所隐含的若干个字符,过滤掉那些多余的比较,将模式串向右“滑动”尽可能远的一段距离后,继续进行比较,从而提高模式匹配的效率,该算法的时间复杂度为O(m+n)。 那么如何确定哪些是多余的比较? 在KMP算法中通过引入前缀函数f(x)来确定每次匹配不需要比较的字符,保证了匹配始终向前进行,无须回溯。假设主串为s1s2,sn.,模式串为t1t2,tm.,其中 m≦n,从si+1开始的子串遇到一个不完全的匹配,使得: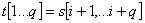
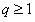 (1.1) 如果我们能确定一个最小的整数
(1.1) 如果我们能确定一个最小的整数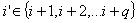 ,使得:
,使得: 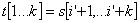 (1.2) 其中
(1.2) 其中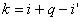 ,所以确定i' 等价于确定k,这里的k值就是我们要求的前缀函数f(x)。由式1.1和1.2中K值与主串s无关,只与给定的模式串t中与主串匹配的q有关,即k=f(q),f(q)=max{i|0 i q且t[1..i]是t[1..q]的后缀} (1.3) 确定KMP前缀函数的算法如下 : #define MAXSIZE 100Typedef unsigned char string[MAXSIZE+1];//0号单元用来存放串的长度void f(sstring t, int *array){ m=t[0];//m为当前模式串的长度 array=(int *)malloc((m+1)*sizeof(int));//0号元不用 array[1]=0;k=0; for(q=2;q<=m;q++) {while(k>0&&t[k+1]!=t[q])k=array[k]; if(t[k+1]==t[q])k=k+1; array[q]=k; }} 关于KMP算法的前缀函数f(x)的示例见表1。
,所以确定i' 等价于确定k,这里的k值就是我们要求的前缀函数f(x)。由式1.1和1.2中K值与主串s无关,只与给定的模式串t中与主串匹配的q有关,即k=f(q),f(q)=max{i|0 i q且t[1..i]是t[1..q]的后缀} (1.3) 确定KMP前缀函数的算法如下 : #define MAXSIZE 100Typedef unsigned char string[MAXSIZE+1];//0号单元用来存放串的长度void f(sstring t, int *array){ m=t[0];//m为当前模式串的长度 array=(int *)malloc((m+1)*sizeof(int));//0号元不用 array[1]=0;k=0; for(q=2;q<=m;q++) {while(k>0&&t[k+1]!=t[q])k=array[k]; if(t[k+1]==t[q])k=k+1; array[q]=k; }} 关于KMP算法的前缀函数f(x)的示例见表1。表1 模式串abaabcac
| I | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Ti | a | b | a | a | b | c | a | c |
| f(i) | 0 | 0 | 1 | 1 | 2 | 0 | 1 | 0 |
当模式串中有i个字符串匹配成功,第i+1个字符不匹配时,则从i-f(i)个字符重新开始比较,这样不仅无须回溯,而且一次可以向前滑动i-f(i)个字符,大大提高了模式匹配的效率。下面给出朴素匹配算法和KMP匹配算法的比较,见表2。表2 朴素匹配算法和KMP匹配算法比较表
| 朴素算法 | KMP算法 | |
| 时间复杂度 | O((n-m+1)m) | O(m+n) |
| 向前移动字符个数 | 1 | q-f(q) |
| 回溯次数 | q-1 | 无 |
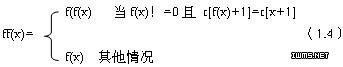 实现此前缀函数的算法是先调用f()函数,根据1.4式对前缀函数进行修改,算法如下:Void ff(sstring t, int *array){ m=t[0]; f (t,array); for(q=1 ;q<=m;q++) { k=f[q]; while(k>0&&t [k+1]==t[q+1]) k=f[k]; f[q]=k }}
实现此前缀函数的算法是先调用f()函数,根据1.4式对前缀函数进行修改,算法如下:Void ff(sstring t, int *array){ m=t[0]; f (t,array); for(q=1 ;q<=m;q++) { k=f[q]; while(k>0&&t [k+1]==t[q+1]) k=f[k]; f[q]=k }} 表3 模式串abaabcac关于改进KMP算法的前缀函数ff(x)的示例
| I | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Ti | a | b | a | a | b | c | a | c |
| ff(i) | 0 | 0 | 1 | 0 | 2 | 0 | 1 | 0 |
两表做比较可以发现:f(4)=1>ff(4)=0 如果前4个字符匹配成功,而第5个字符匹配失败,那么改进后的重新匹配次数要减少一次,提高了效率。
3 利用改进算法实现多次模式匹配
在实际应用中,模式串与主串一般要进行多次匹配,以便找到在主串含有多少个这样的子串,典型的应用就是在数据库中的查找。例如输入某人的姓名,然后在姓名这一主串内查找有多少个这样的子串。下面结合前缀函数ff(x)的求解算法给出多次模式匹配的算法: void match(string s,string t, int a[]){ n=s[0];//主串的长度 m=t.[0];//模式串的长度 ff(t,f)//求出模式串中各个字符的前缀函数ff(x) d=0;//该变量用来统计与模式串匹配成功的子串的个数 q=0//该变量表示模式串中与主串匹配成功的字符的个数for(i=1;i<=n;i++) { while(q>0&&t[q+1]!=s[i]) q=f[q]; if(t[q+1]==s[i]) q=q+1; if(q==m) {d=d+1; a[d]=i-m+1;} }}4 结 语
本文给出的算法较朴素匹配算法在效率上有了较大的提高,尤其是对重复字符出现较少的数据段进行模式匹配可取得较高的查找效率。应用于大型数据库的数据查询,会更加有效地缩短查找时间。[1]严蔚敏,吴伟民.数据结构[M].清华大学出版社, 2001[2]傅清祥,王晓东.算法与数据结构[M].出版社,1998[3]D.Wood,DataStructures,AlgorithmsAndPerfomance,Reading,MA:AddisonWesley,1993[4]onnetGH.HandbookofAlgorithmsAndDataStructure[M].Addison-WesleyPublishingCompany,1999下一篇:安全处理器的研究