基于模糊理论的图像分割算法研究(四)
6.4实验结论
本文所讨论的基于遗传算法的图像分割算法,采用标准遗传算法作为流程,但对其中的选择算子进行了改变,用高级选择函数select代替了传统的单一选择算子,使得在每次选择运算后所得的父辈更为健壮,更好的保持了第一代父辈的表现型,使得分割更加精确。通过设计变异概率,使得每次迭代遗传运算后,子代的表现型略有改变,从而更以获得最优的表现型(即最优阈值),减少了迭代寻优次数,降低了程序运行时间。同时考虑到过多迭代不利于降低程序运行时间,以及在寻优过程中的最佳值收敛问题,指定迭代次数为50次时即跳出整个程序,通过反编码求得最优阈值,并通过变量调用,直接应用于下面的分割程序,达到了整个算法的自动完成。
相对于灰度直方图双峰法,本方法对图像的先验信息要求不高,不需要像灰度直方图法那样,先通过获得图像的灰度直方图取得分割阈值后再对图像处理,整个程序的自动化程度高,且对于那些灰度直方图不呈双峰分布的图像,本算法程序一样可以处理,这就扩大了本算法程序的灵活性,从而更具有实际意义。而且,由于灰度直方图双峰法的阈值是通过人眼观察获得,其误差必然大于机器迭代运算所取得的最优阈值,而普通的阈值分割法,如ostu法,虽然实现了阈值的自动选择,但其运算时间与本算法相比偏长,实时性差于本算法。因此,在图像分割算法中,基于遗传算法的图像分割算法更优于其它传统的图像分割算法。
通过上述讨论,以及两种方法的处理结果图片的对比,基于遗传算法的最大类间方差法分割后图像与直方图双峰法分割后的图像像比,效果更明显,且无须事先测量图像的灰度直方图,更加灵活,更加精确。
其相关试验结论列于下表:
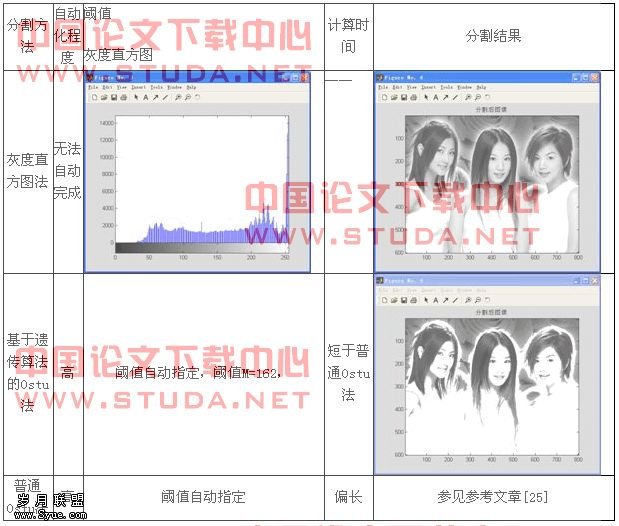
基于遗传算法的图象分割实验结论总表:
分割方法
自动化程度
阈值
灰度直方图
计算时间
分割结果
灰度直方图法
无法自动完成
——
基于遗传算法的Ostu法
高
阈值自动指定,阈值M=162,
短于普通Ostu法
普通Ostu法
高
阈值自动指定
偏长
参见文章[25]
参 考 文 献
[1]张兆礼,赵春晖,梅晓丹.图像处理技术及MAThAB实现.北京:人民邮电出版社,2001.1
[2]陈传波,金先级.数字图像处理[M].北京:机械出版社,2004.
[3]夏德深,傅德胜等.现代图象处理技术与应用[M].南京:东南大学出版社,1997.
[4]章毓晋.图象工程(上册)图象处理和分析.北京:清华大学出版社,1999.
[5]王小平,曹立明.遗传算法理论、应用与软件实现.西安:西安交大出版社,2002.
[6]徐立中,数字图像的智能信息处理。北京:国防工业出版社,2001
[7]王耀南,李树涛,毛建旭,计算机图像处理与识别技术,北京:高等出版社,2001
[8]雷英杰,张善文,李绪武,周创明.MATLAB遗传算法工具箱及应用,西安:西安科技大学出版社
[9]何新贵.模糊知识处理的理论与计算,国防工业出版社,1999
[10]徐建华.图像处理与分析,北京:出版,1992.
[11]阮秋琦.数字图象处,电子工业出版社,2001
[12]王博等.图像平滑与边缘检测的模糊向量描述,小型微型计算机统,Vol. 20(3), 1999
[13]吴谨,李娟,刘成云,基于最大熵的灰度阈值选取方法,武汉科技大学学报(科学版),Vol. 27, No. 1, Mar, 2004
[14]李鉴庆,左坤隆,图像阈值选取的一种快速算法.计算机与现代化,2001年第6期
[15]魏宝刚,鲁东明,潘云鹤等.多颜色空间上的互式图像分割[J].计算机学报,2001, 24 (7):770-775
[16]杜亚勤,基于模糊集的图像边缘检测技术研究:[硕士学位].西安:西安工业学院,2004年4月
[17]王保平,基于模糊技术的图像处理方法研究[博士学位论文],西安:西安电子科技大学,2004, 9
[18]杜亚娟,潘泉,周德龙等,图像多级灰度非线性模糊增强算法研究,数据采集与处Vo1.14 No.2
[19]Russ J C, The image processing handbook. New York:CRC Press,1994
[20]L A Zadeh.Fuzzy Sets[J].Information and Contro1,1965, (8):338-353
[21]Lotfi A.Zadeh,A fuzzy-set-theoretic interpretation of linguistic hedges, Journal of Cybernetic, 1972, 64(2):4-34
[22]S. K. Pal, R. A. King. Image Enhancement Using Fuzzy Sets. Electron. Let t.,1980 16 (9):376-378.
[23]S. K. PaI, R. :A. King, On Edge Detection of R-Ray Images Using Fuzzy Sets. IEEE Trans.Patt. Anal and MachineIntell.1983,PAMI-5 (1):69-77.
[24]Otsu N. A Threshold Selection Method From Gray Level Histograms. IEEE Trans on Syst Man Cybernet, 1979, SMC-9:62-66
附 录 附录 一
灰度直方图双峰法分割源代码
clear, close all
B=imread('2.jpg'); %读入原始jpg格式图像
figure(1);
imshow(B),title('原始jpg格式图像');
I1=rgb2gray(B); %将原图像转化为灰度图象
figure(2);
imshow(I1),title('灰度格式图像');
[I1,map1]=gray2ind(I1,255); %将灰度图像转化为索引图像
figure(3), imhist(I1) %画出灰度直方图,以判断域值
I1=double(I1); %将unit8数组转化为double型数组
Z=I1 %将double型数组I1转存到Z中
[m, n]=size(Z);
for i=1:m
for j=1:n
if Z(i,j)>240 %灰度值大于域值时是白色
Z(i,j)=256;
end
end
end
figure(4) %画出分割后目标图像
image(Z),title('分割后图像');colormap(map1);
图像I图像格式转化及灰度直方图双峰法分割源代码
clear, close all
B=imread('she.jpg'); %读入原始jpg格式图像she
figure(1);
imshow(B),title('原始jpg格式图像');
I1=rgb2gray(B); %将原图像转化为灰度图象
figure(2);
imshow(I1),title('灰度格式图像');
[I1,map1]=gray2ind(I1,255); %将灰度图像转化为索引图像
figure(3), imhist(I1) %画出灰度直方图,以判断域值
I1=double(I1); %将unit8数组转化为double型数组
Z=I1 %将double型数组I1转存到Z中
[m, n]=size(Z);
for i=1:m
for j=1:n
if Z(i,j)>240 %灰度值大于域值时是白色
Z(i,j)=256;
end
end
end
figure(4) %画出分割后目标图像
image(Z),title('分割后图像');colormap(map1);
图像II图像格式转化及灰度直方图双峰法分割源代码
clear, close all
B=imread('she.jpg'); %读入原始jpg格式图像月亮
figure(1);
imshow(B),title('原始jpg格式图像');
I1=rgb2gray(B); %将原图像转化为灰度图象
figure(2);
imshow(I1),title('灰度格式图像');
[I1,map1]=gray2ind(I1,255); %将灰度图像转化为索引图像
figure(3), imhist(I1) %画出灰度直方图,以判断域值
I1=double(I1); %将unit8数组转化为double型数组
Z=I1 %将double型数组I1转存到Z中
[m, n]=size(Z);
for i=1:m
for j=1:n
if Z(i,j)>240 %灰度值大于域值时是白色
Z(i,j)=256;
end
end
end
figure(4) %画出分割后目标图像
image(Z),title('分割后图像');colormap(map1);
附录 二
Crtbp 函数源代码:(由谢菲尔德大学Andrew Chipperfield编写)
% CRTBP.m - Create an initial population%
% This function creates a binary population of given size and structure.
%
% Syntax: [Chrom Lind BaseV] = crtbp(Nind, Lind, Base)
%
% Input Parameters:
%
% Nind - Either a scalar containing the number of individuals
% in the new population or a row vector of length two
% containing the number of individuals and their length.
%
% Lind - A scalar containing the length of the individual
% chromosomes.
%
% Base - A scalar containing the base of the chromosome
% elements or a row vector containing the base(s)
% of the loci of the chromosomes.
%
% Output Parameter
s:
%
% Chrom - A matrix containing the random valued chromosomes
% row wise.
%
% Lind - A scalar containing the length of the chromosome.
%
% BaseV - A row vector containing the base of the
% chromosome loci.
% Author: Andrew Chipperfield
% Date: 19-Jan-94
function [Chrom, Lind, BaseV] = crtbp(Nind, Lind, Base)
nargs = nargin ;
% Check parameter consistency
if nargs >= 1, [mN, nN] = size(Nind) ; end
if nargs >= 2, [mL, nL] = size(Lind) ; end
if nargs == 3, [mB, nB] = size(Base) ; end
if nN == 2
if (nargs == 1)
Lind = Nind(2) ; Nind = Nind(1) ; BaseV = crtbase(Lind) ;
elseif (nargs == 2 & nL == 1)
BaseV = crtbase(Nind(2),Lind) ; Lind = Nind(2) ; Nind = Nind(1) ;
elseif (nargs == 2 & nL > 1)
if Lind ~= length(Lind), error('Lind and Base disagree'); end
BaseV = Lind ; Lind = Nind(2) ; Nind = Nind(1) ;
end
elseif nN == 1
if nargs == 2
if nL == 1, BaseV = crtbase(Lind) ;
else, BaseV = Lind ; Lind = nL ; end
elseif nargs == 3
if nB == 1, BaseV = crtbase(Lind,Base) ;
elseif nB ~= Lind, error('Lind and Base disagree') ;
else BaseV = Base ; end
end
else
error('Input parameters inconsistent') ;
end
% Create a structure of random chromosomes in row wise order, dimensions
% Nind by Lind. The base of each chromosomes loci is given by the value
% of the corresponding element of the row vector base.
Chrom = floor(rand(Nind,Lind).*BaseV(ones(Nind,1),:)) ;
% End of file
附录 三
Bs2rv函数源代码: (由谢菲尔德大学Andrew Chipperfield编写)
% BS2RV.m - Binary string to real vector
%
% This function decodes binary chromosomes into vectors of reals. The
% chromosomes are seen as the concatenation of binary strings of given
% length, and decoded into real numbers in a specified interval using
% either standard binary or Gray decoding.
%
% Syntax: Phen = bs2rv(Chrom,FieldD)
%
% Input parameters:
%
% Chrom - Matrix containing the chromosomes of the current
% population. Each line corresponds to one
% individual's concatenated binary string
% representation. Leftmost bits are MSb and
% rightmost are LSb.
%
% FieldD - Matrix describing the length and how to decode
% each substring in the chromosome. It has the
% following structure:
%
% [len; (num)
% lb; (num)
% ub; (num)
% code; (0=binary | 1=gray)
% scale; (0=arithmetic | 1=logarithmic)
% lbin; (0=excluded | 1=included)
% ubin]; (0=excluded | 1=included)
%
% where
% len - row vector containing the length of
% each substring in Chrom. sum(len)
% should equal the individual length.
% lb,
% ub - Lower and upper bounds for each
% variable.
% code - binary row vector indicating how each
% substring is to be decoded.
% scale - binary row vector indicating where to
% use arithmetic and/or logarithmic
% scaling.
% lbin,
% ubin - binary row vectors indicating whether
% or not to include each bound in the
% representation range
%
% Output parameter:
%
% Phen - Real matrix containing the population phenotypes.
%
% Author: Carlos Fonseca, Updated: Andrew Chipperfield
% Date: 08/06/93, Date: 26-Jan-94
function Phen = bs2rv(Chrom,FieldD)
% Identify the population size (Nind)
% and the chromosome length (Lind)
[Nind,Lind] = size(Chrom);
% Identify the number of decision variables (Nvar)
[seven,Nvar] = size(FieldD);
if seven ~= 7
error('FieldD must have 7 rows.');
end
% Get substring properties
len = FieldD(1,:);
lb = FieldD(2,:);
ub = FieldD(3,:);
code = ~(~FieldD(4,:));
scale = ~(~FieldD(5,:));
lin = ~(~FieldD(6,:));
uin = ~(~FieldD(7,:));
% Check substring properties for consistency
if sum(len) ~= Lind,
error('Data in FieldD must agree with chromosome length');
end
if ~all(lb(scale).*ub(scale)>0)
error('Log-scaled variables must not include 0 in their range');
end
% Decode chromosomes
Phen = zeros(Nind,Nvar);
lf = cumsum(len);
li = cumsum([1 len]);
Prec = .5 .^ len;
logsgn = sign(lb(scale));
lb(scale) = log( abs(lb(scale)) );
ub(scale) = log( abs(ub(scale)) );
delta = ub - lb;
Prec = .5 .^ len;
num = (~lin) .* Prec;
den = (lin + uin - 1) .* Prec;
for i = 1:Nvar,
idx = li(i):lf(i);
if code(i) % Gray decoding
Chrom(:,idx)=rem(cumsum(Chrom(:,idx)')',2);
end
Phen(:,i) = Chrom(:,idx) * [ (.5).^(1:len(i))' ];
Phen(:,i) = lb(i) + delta(i) * (Phen(:,i) + num(i)) ./ (1 - den(i));
end
expand = ones(Nind,1);
if any(scale)
Phen(:,scale) = logsgn(expand,:) .* exp(Phen(:,scale));
end
附录 四
适应度函数target源代码:
function f=target(T,M) %适应度函数,T为待处理图像,M为域值序列
[U, V]=size(T);
W=, , length(M);
f=zeros(W,1);
for k=1:W
I=0;s1=0;J=0;s2=0; %统计目标图像和背景图像的像素数及像素之和
for i=1:U
for j=1:V
if T(i,j)<=M(k)
s1=s1+T(i,j);I=I+1;
end
if T(i,j)>M(k)
s2=s2+T(i,j);J=J+1;
end
end
end
if I==0, p1=0; else p1=s1/I; end
if J==0, p2=0; else p2=s2/J; end
f(k)=I*J*(p1-p2)*(p1-p2)/(256*256);
end
附录 五
选择函数Select源代码:(由谢菲尔德大学Hartmut Pohlheim编写)
% SELECT.M (universal SELECTion)
%
% This function performs universal selection. The function handles
% multiple populations and calls the low level selection function
% for the actual selection process.
%
% Syntax: SelCh = select(SEL_F, Chrom, FitnV, GGAP, SUBPOP)
%
% Input parameters:
% SEL_F - Name of the selection function
% Chrom - Matrix containing the individuals (parents) of the current
% population. Each row corresponds to one individual.
% FitnV - Column vector containing the fitness values of the
% individuals in the population.
% GGAP - (optional) Rate of individuals to be selected
% if omitted 1.0 is assumed
% SUBPOP - (optional) Number of subpopulations
% if omitted 1 subpopulation is assumed
%
% Output parameters:
% SelCh - Matrix containing the selected individuals.
% Author: Hartmut Pohlheim
% History: 10.03.94 file created
function SelCh = select(SEL_F, Chrom, FitnV, GGAP, SUBPOP);
% Check parameter consistency
if nargin < 3, error('Not enough input parameter'); end
% Identify the population size (Nind)
[NindCh,Nvar] = size(Chrom);
[NindF,VarF] = size(FitnV);
if NindCh ~= NindF, error('Chrom and FitnV disagree'); end
if VarF ~= 1, error('FitnV must be a column vector'); end
if nargin < 5, SUBPOP = 1; end
if nargin > 4,
if isempty(SUBPOP), SUBPOP = 1;
elseif isnan(SUBPOP), SUBPOP = 1;
elseif length(SUBPOP) ~= 1, error('SUBPOP must be a scalar'); end
end
if (NindCh/SUBPOP) ~= fix(NindCh/SUBPOP), error('Chrom and SUBPOP disagree'); end
Nind = NindCh/SUBPOP; % Compute number of individuals per subpopulation
if nargin < 4, GGAP = 1; end
if nargin > 3,
if isempty(GGAP), GGAP = 1;
elseif isnan(GGAP), GGAP = 1;
elseif length(GGAP) ~= 1, error('GGAP must be a scalar');
elseif (GGAP < 0), error('GGAP must be a scalar bigger than 0'); end
end
% Compute number of new individuals (to select)
NSel=max(floor(Nind*GGAP+.5),2);
% Select individuals from population
SelCh = [];
for irun = 1:SUBPOP,
FitnVSub = FitnV((irun-1)*Nind+1:irun*Nind);
ChrIx=feval(SEL_F, FitnVSub, NSel)+(irun-1)*Nind;
SelCh=[SelCh; Chrom(ChrIx,:)];
end
% End of function
附录 六
交叉函数recombin的源代码:(由谢菲尔德大学Hartmut Pohlheim编写)
% RECOMBIN.M (RECOMBINation high-level function)
%
% This function performs recombination between pairs of individuals
% and returns the new individuals after mating. The function handles
% multiple populations and calls the low-level recombination function
% for the actual recombination process.
%
% Syntax: NewChrom = recombin(REC_F, OldChrom, RecOpt, SUBPOP)
%
% Input parameters:
% REC_F - String containing the name of the recombination or
% crossover function
% Chrom - Matrix containing the chromosomes of the old
% population. Each line corresponds to one individual
% RecOpt - (optional) Scalar containing the probability of
% recombination/crossover occurring between pairs
% of individuals.
% if omitted or NaN, 1 is assumed
% SUBPOP - (optional) Number of subpopulations
% if omitted or NaN, 1 subpopulation is assumed
%
% Output parameter:
% NewChrom - Matrix containing the chromosomes of the population
% after recombination in the same format as OldChrom.
% Author: Hartmut Pohlheim
% History: 18.03.94 file created
function NewChrom = recombin(REC_F, Chrom, RecOpt, SUBPOP);
% Check parameter consistency
if nargin < 2, error('Not enough input parameter'); end
% Identify the population size (Nind)
[Nind,Nvar] = size(Chrom);
if nargin < 4, SUBPOP = 1; end
if nargin > 3,
if isempty(SUBPOP), SUBPOP = 1;
elseif isnan(SUBPOP), SUBPOP = 1;
elseif length(SUBPOP) ~= 1, error('SUBPOP must be a scalar'); end
end
if (Nind/SUBPOP) ~= fix(Nind/SUBPOP), error('Chrom and SUBPOP disagree'); end
Nind = Nind/SUBPOP; % Compute number of individuals per subpopulation
if nargin < 3, RecOpt = 0.7; end
if nargin > 2,
if isempty(RecOpt), RecOpt = 0.7;
elseif isnan(RecOpt), RecOpt = 0.7;
elseif length(RecOpt) ~= 1, error('RecOpt must be a scalar');
elseif (RecOpt < 0 | RecOpt > 1), error('RecOpt must be a scalar in [0, 1]'); end
end
% Select individuals of one subpopulation and call low level function
NewChrom = [];
for irun = 1:SUBPOP,
ChromSub = Chrom((irun-1)*Nind+1:irun*Nind,:);
NewChromSub = feval(REC_F, ChromSub, RecOpt);
NewChrom=[NewChrom; NewChromSub];
end
% End of function
附录 七
变异函数mut源代码 :(由谢菲尔德大学Andrew Chipperfield编写)
% MUT.m
%
% This function takes the representation of the current population,
% mutates each element with given probability and returns the resulting
% population.
%
% Syntax: NewChrom = mut(OldChrom,Pm,BaseV)
%
% Input parameters:
%
% OldChrom - A matrix containing the chromosomes of the
% current population. Each row corresponds to
% an individuals string representation.
%
% Pm - Mutation probability (scalar). Default value
% of Pm = 0.7/Lind, where Lind is the chromosome
% length is assumed if omitted.
%
% BaseV - Optional row vector of the same length as the
% chromosome structure defining the base of the
% individual elements of the chromosome. Binary
% representation is assumed if omitted.
%
% Output parameter:
%
% NewChrom - A Matrix containing a mutated version of
% OldChrom.
%
% Author: Andrew Chipperfield
% Date: 25-Jan-94
function NewChrom = mut(OldChrom,Pm,BaseV)
% get population size (Nind) and chromosome length (Lind)
[Nind, Lind] = size(OldChrom) ;
% check input parameters
if nargin < 2, Pm = 0.7/Lind ; end
if isnan(Pm), Pm = 0.7/Lind; end
if (nargin < 3), BaseV = crtbase(Lind); end
if (isnan(BaseV)), BaseV = crtbase(Lind); end
if (isempty(BaseV)), BaseV = crtbase(Lind); end
if (nargin == 3) & (Lind ~= length(BaseV))
error('OldChrom and BaseV are incompatible'), end
% create mutation mask matrix
BaseM = BaseV(ones(Nind,1),:) ;
% perform mutation on chromosome structure
NewChrom = rem(OldChrom+(rand(Nind,Lind)<Pm).*ceil(rand(Nind,Lind).*(BaseM-1)),BaseM);
附录 八
基于遗传算法的最大类间方差法对JPG格式图像分割的程序源代码:
clear, close all
B=imread('she.jpg'); %读入原始jpg格式图像
figure(1);
imshow(B),title('原始jpg格式图像');
I1=rgb2gray(B); %将原图像转化为灰度图象
figure(2);
imshow(I1),title('灰度格式图像');
BW1 = edge(I1,'sobel');
BW2 = edge(I1,'canny');
figure(6),imshow(BW1),title('边缘检测1'); %边缘检测
figure(5), imshow(BW2),title('边缘检测2');
[I1,map1]=gray2ind(I1,255); %将灰度图像转化为索引图像
I1=double(I1); %将unit8数组转化为double型数组
Z=I1 %将double型数组I1转存到Z中
figure(3) %画出未进行分割的原始图像
image(Z),title('未进行分割的原始图像');colormap(map1);
NIND=40; %个体
数目(Number of individuals)
MAXGEN=50; %最大遗传代数(Maximum number of generations)
PRECI=8; %变量的二进制位数(Precision of variables)
GGAP=0.9; %代沟(Generation gap)
FieldD=[8;1;256;1;0;1;1]; %建立区域描述器(Build field descriptor)
Chrom=crtbp(NIND,PRECI); %创建初始种群
gen=0;
phen=bs2rv(Chrom,FieldD); %初始种群十进制转换
ObjV=target(Z,phen); %种群适应度值
while gen<MAXGEN %代沟(Generation gap)
FitnV=ranking(-ObjV); %分配适应度值(Assign fitness values)
SelCh=select('sus',Chrom,FitnV,GGAP); %选择
SelCh=recombin('xovsp',SelCh,0.7); %重组
SelCh=mut(SelCh); %变异
phenSel=bs2rv(SelCh,FieldD); %子代十进制转换
ObjVSel=target(Z,phenSel);
[Chrom ObjV]=reins(Chrom,SelCh,1,1,ObjV,ObjVSel); %重插入
gen=gen+1;
end
[Y, I]=max(ObjV);
M=bs2rv(Chrom(I,:),FieldD); %估计域值
[m, n]=size(Z);
for i=1:m
for j=1:n
if Z(i,j)>M %灰度值大于域值时是白色
Z(i,j)=256;
end
end
end
figure(4) %画出分割后目标图像
image(Z),title('分割后图像');colormap(map1);
target求适应度函数代码:
function f=target(T,M) %适应度函数,T为待处理图像,M为域值序列
[U, V]=size(T);
W=length(M);
f=zeros(W,1);
for k=1:W
I=0;s1=0;J=0;s2=0; %统计目标图像和背景图像的像素数及像素之和
for i=1:U
for j=1:V
if T(i,j)<=M(k)
s1=s1+T(i,j);I=I+1;
end
if T(i,j)>M(k)
s2=s2+T(i,j);J=J+1;
end
end
end
if I==0, p1=0; else p1=s1/I; end
if J==0, p2=0; else p2=s2/J; end
f(k)=I*J*(p1-p2)*(p1-p2)/(256*256);
end;